Web爬行
当大多数人谈论互联网搜索引擎,他们真正的意思是万维网搜索引擎。在网络成为互联网最明显的部分,已经有搜索引擎来帮助人们找到信息在网上。18luck手机登录项目与“地鼠”和“奇”等名称保存索引的文件存储在服务器连接互联网,大大降低了所需的时间找到程序和文档。在1980年代末,从互联网上获得严重的价值意味着知道如何使用金花鼠,Archie,维罗妮卡和休息。18新利最新登入
今天,大多数互联网用户限制他们的搜索网络,因此我们将限制本文搜索引擎关注的内容网页。
广告
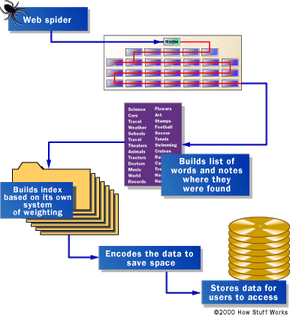
之前一个搜索引擎可以告诉你一个文件或文档,它必须被发现。找信息存在的数以18luck手机登录百万计的网页,搜索引擎使用特殊软件机器人,叫道蜘蛛,构建列表在网站找到。当蜘蛛建立的列表,这个过程被称为Web爬行。(有一些缺点调用的一部分网络万维网——大量arachnid-centric名称工具就是其中之一。)为了建立和维护一个有用的单词列表,搜索引擎的蜘蛛要看大量的页面。
18新利最新登入如何任何蜘蛛开始它的传播在网络上?通常的起点是大量使用的列表服务器和非常受欢迎的页面。蜘蛛将开始与一个受欢迎的网站,索引词的页面和网站上的每一个环节中找到。这样,搜索系统迅速开始旅行,蔓延在使用最广泛的网络部分。
谷歌开始作为一个学术搜索引擎。本文描述了系统建成,谢尔盖•布林(Sergey Brin18新利最新登入)和劳伦斯页面给他们的蜘蛛能多快的一个例子。他们建造了他们最初的系统使用多个蜘蛛,通常三个一次。每个蜘蛛可以保持约300连接到Web页面打开一次。峰值性能,使用四个蜘蛛,他们的系统会爬每秒超过100页,每秒钟产生大约600字节的数据。
保持一切运行快速意味着建立一个系统来满足蜘蛛的必要信息。18luck手机登录谷歌早期系统有一个服务器致力于为蜘蛛提供url。而不是取决于一个互联网服务提供商为域名服务器(DNS),将服务器的名称转换为一个地址,谷歌有自己的DNS,为了保持延迟降到最低。
当谷歌蜘蛛看着一个HTML页面,它注意到两件事:
- 在页面内
- 单词被发现
词出现在标题、副标题,元标记和其他位置的相对重要性是指出特别考虑在随后的用户搜索。谷歌蜘蛛是建立索引页面上的每一个重要词,离开了文章“,”“一个”和“。”Other spiders take different approaches.
这些不同的方法通常试图让蜘蛛运作更快,允许用户搜索更有效,或两者兼而有之。例如,一些蜘蛛将跟踪字的标题、子标题和链接,以及页面上的100个最常用的单词,每个单词的第一个20行文本。莱科思是说使用这种方法来搜索网络。
其他系统,如AltaVista,去另一个方向,索引页面上的每一个字,包括“一”,“一个”,“”和其他“微不足道”的单词。推动完整性在这种方法相匹配的其他系统关注的看不见的部分网页,meta标记。了解更多关于元标记在下一页。


