语音识别和统计建模
早期的语音识别系统试图应用一组语法句法规则的演讲。如果单词符合一定的规则集,该程序可以确定的话。18新利最新登入然而,人类的语言有许多例外它自己的规则,即使是一致。口音、方言和言谈举止能大大改变某些词或短语说话的方式。从波士顿想象有人说“谷仓。”He wouldn't pronounce the "r" at all, and the word comes out rhyming with "John." Or consider the sentence, "I'm going to see the ocean." Most people don't enunciate their words very carefully. The result might come out as "I'm goin' da see tha ocean." They run several of the words together with no noticeable break, such as "I'm goin'" and "the ocean." Rules-based systems were unsuccessful because they couldn't handle these variations. This also explains why earlier systems could not handle continuous speech -- you had to speak each word separately, with a brief pause in between them.
今天的语音识别系统使用强大的和复杂的统计建模系统。这些系统使用概率和数学函数来确定最可能的结果。根据约翰•Garofolo演讲组管理器信息技术实验室的国家标准与技术研究院今天主宰战场的两个模型的隐马尔科夫模型18luck手机登录和神经网络。这些方法涉及到复杂的数学函数,但从本质上讲,他们知道的信息系统找出隐藏的信息。18luck手机登录
广告
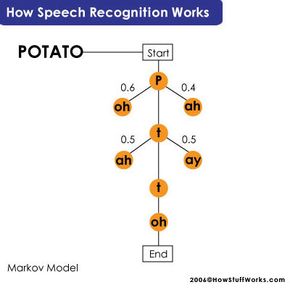
隐马尔科夫模型是最常见的,所以我们要仔细看看这个过程。在这个模型中,每个音素就像一个链接链,完成链是一个字。18新利最新登入然而,链分支在不同的方向项目尝试匹配的数字声音未来最有可能的音素。在这个过程中,每个音素的程序分配一个概率评分,根据其内置的词典和用户培训。
这个过程是更加复杂的短语和句子——系统必须找出每个单词停止和开始。典型的例子是“识别语音,“这听起来很像“破坏一个漂亮的海滩”当你说它很快。程序使用短语分析音素,之前为了得到它。这里有一个分解的两个短语:
r呃k ao g n ay z s p iy ch
“认识到演讲”
r呃k ay n ay s b iy ch
“破坏一个漂亮的海滩
这是为什么这么复杂?如果一个程序有60000字的词汇(常见的在今天的项目),216万亿年三个词的序列可以是任何可能性。显然,即使是最强大的计算机搜索都不能没有一些帮助。
帮助项目培训的形式。根据约翰Garofolo:
而软件开发人员设置系统最初的词汇表执行大部分的训练,最终用户也必须花一些时间培训。在商业环境中,主用户程序必须花一些时间(有时仅为10分钟)说到系统训练他们的特定的语言模式。他们还必须培养系统识别特定公司术语和缩写。特殊版本的语音识别程序中常用的医学或法律办公室术语这些字段已经训练了。
接下来,我们将看看一些语音识别系统的弱点和缺陷。